생성형 인공지능(AI) 모델에 학습된 데이터가 영어, 일본어, 중국어 등 타 언어 대비 한국어 관련 정답률이 상대적으로 낮은 것으로 나타났다. 영어 대비 언어별 평균 토큰 비율 분석 결과, 한국어는 평균 2.36배 가장 높은 수치를 기록하며 거대언어모델(LLM) 중 가장 비효율적인 언어로 나타났다. 이에 따라 한국 역사 관련 질문에서는 일본, 중국 등 국가에 편향적인 결과가 나오고 있다.
12일 AI 업계에 따르면 미국 오픈AI의 챗GPT, xAI의 그록3, 마이크로소프트의 코파일럿 등 주요 생성형 AI가 일본과 중국 중심의 역사·지리 인식을 보이고 있다. 한국어는 AI 학습에 투입된 데이터의 양과 질 모두에서 열위에 있는 것으로 분석된다. 특히 동해를 일본해로 표기하는 등 언어 분포도에서 비롯된 역사적 사실 전달 오류는 정보를 취득하는 학생 등 사용자들이 왜곡된 내용을 받아들일 위험성을 내포하고 있다.
올해 4월 최신 업데이트된 추론형 모델인 챗GPT o3 역시 동해에 관한 질문에 일본 위키피디아 정보를 근거로 설명한 것으로 알려졌다.
챗GPT는 지도 생성시 ‘동해’를 ’일본해(Sea of Japan)’로 표기하며 국제적 용례를 이유로 들었고, 그록3와 코파일럿은 독도를 ‘리앙크루 암초’ 혹은 ‘다케시마’로 표현했다. 중국 AI 딥시크는 고구려와 발해가 중국 고대사에 속하며 중국 문명의 영향을 받았다고 답변한다.
국가별 '대규모 다중작업 언어이해 평가(MMLU) 점수, 투입된 데이터 양, 알고리즘 특성이 일부 답변에 기술적으로 영향을 미치는 것으로 분석된다.
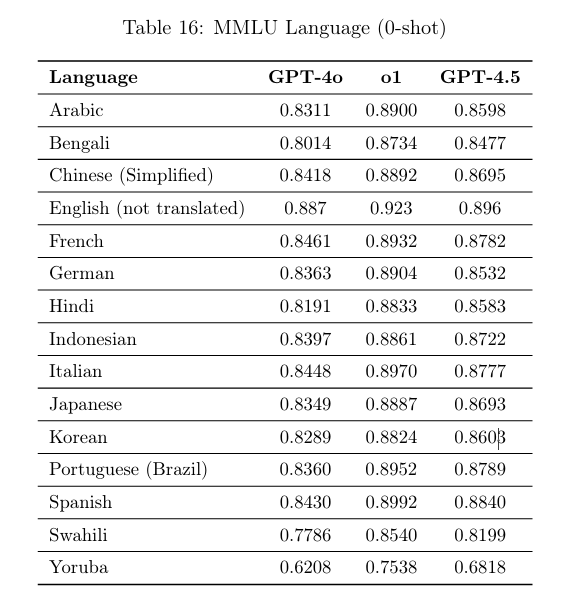
올해 2월 오픈AI가 공개한 기술 리포트에 따르면 최신 GPT-4.5 모델의 MMLU 평가에서 영어가 0.896으로 가장 높았고 중국어와 일본어는 각각 0.8695, 0.8693으로 비슷한 수준을 기록했다. 그다음으로 한국어는 0.8603으로 소폭 낮은 점수를 보였다.
추론형 모델인 GPT-4o1 역시 영어(0.923)가 가장 높은 수치를 기록했고 이어 중국어(0.8892), 일본어(0.8887), 한국어(0.8824) 순이었다.
이 같은 언어별 성능 차이는 학습에 투입된 데이터 양과 질의 차이를 반영하는 것이며 영어 중심인 주요 언어에 비해 한국어 학습 데이터가 상대적으로 적다는 주장도 제기된다.

연구 결과 GPT 계열의 대형 언어 모델(LLM)의 한국어 처리도 다른 언어 대비 상대적으로 비효율적인 구조를 보였다. 'CJK LLM Best Practices' 분석 자료에 따르면 언어별 번역문 토큰 비율 비교에서 한국어가 영어 대비 평균 2.36배 많은 토큰을 사용하는 것으로 나타났다. 이어 광둥어(2.10배), 일본어(2.12배), 중국어(북경어, 1.76배) 순으로 높은 토큰 비율을 보였다.
반면 프랑스어(1.45배), 독일어(1.39배), 스페인어(1.32배) 등 유럽권 언어는 상대적으로 낮은 비율을 기록해 LLM 환경에서 더 효율적으로 처리되는 것으로 분석된다. 특히 한국어는 일본어나 중국어보다도 더 많은 토큰을 필요로 해, 글로벌 언어 모델이 한국어를 다룰 때 구조적으로 불리한 조건에 놓여 있음을 시사한다.

연세대학교, KAIST, 네이버 클라우드 등 연구진이 참여한 KMMLU 연구에 따르면 한국사 문제를 풀도록 한 실험에서 GPT4의 정답률은 35%에 그친 반면, 한국어에 특화된 대형 언어 모델인 하이퍼클로바X는 44%의 정답률을 기록했다. 전문가들은 이러한 차이가 GPT-4의 한국어 이해도가 낮기 때문이라며, 한국어에 특화된 학습 데이터와 프롬프트 설계가 필수적이라고 지적하고 있다.


최연재·나선혜 기자ch0221@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



