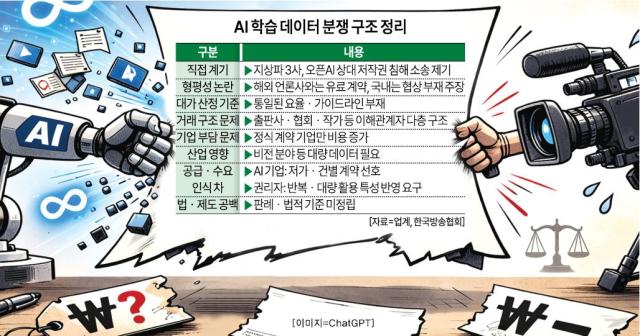
지상파 3사(KBS·MBC·SBS)가 생성형 인공지능(AI) 학습을 둘러싼 저작권 침해를 주장하며 소송에 나섰다. AI 학습 데이터 활용에 대한 대가 산정 기준이 마련되지 않은 상황에서 업계 갈등이 결국 법적 분쟁으로 번지는 양상이다.
23일 한국방송협회에 따르면 지상파 3사는 자사 뉴스 콘텐츠가 챗GPT 학습에 무단 활용됐다며 오픈AI를 상대로 저작권 침해 중단 및 손해배상 청구 소송을 제기했다. 국내 방송사가 글로벌 AI 기업을 상대로 소송을 제기한 것은 이번이 처음이다.
방송 3사는 오픈AI가 뉴스코퍼레이션 등 해외 언론사와는 유료 라이선스 계약을 체결한 반면, 국내 언론사와의 협상에는 응하지 않고 있다고 주장했다. 정당한 보상 체계가 마련되지 않은 상태에서 국내 언론 콘텐츠가 AI 학습에 활용됐다는 점에서 형평성 문제가 제기되고 있다.
문제의 배경에는 AI 학습에 적용할 대가 산정 기준이 마련되지 않았다는 점이 자리한다. 업계에 따르면 현재 AI 학습용 데이터에는 통일된 요율이나 산정 방식이 없다. 한 업계 관계자는 "AI 학습을 위한 데이터 구매 시 정해진 가격은 없으며 각 유통사나 협회마다 가격을 책정하는 방식도 규격화돼 있지 않다"며 "가격이 분량으로 정해지는 것도 아닌 상황"이라고 말했다.
이로 인해 일각에서는 '양심적으로 계약을 체결하고 학습 데이터를 확보하는 기업만 비용 부담이 커지는 구조'라는 지적도 제기된다. 이미지·영상과 같은 비전 분야처럼 대량 데이터가 필수인 영역에서는 데이터 학습에 대한 비용과 협상 부담이 AI 고도화 속도를 늦출 수 있다는 우려도 나온다.
공급자와 수요자 간 가격 인식 차도 갈등을 키우는 요인으로 꼽힌다. 수요자인 AI 사업자는 연구 목적의 데이터는 무료로 상업용은 단건 계약이나 싸게 이용하자는 입장이다. 반면 저작권자, 출판업계 등을 포함한 공급자들은 무한이 인용하는 데이터 특성상 싼 가격의 계약은 불가하는 설명이다.
시장 자율에 맡겨서는 적정 가격을 도출하기 어렵다는 지적도 나온다. AI 데이터 학습 행위에 대한 명확한 법적 기준이 아직 정립되지 않았기 때문이다. 김기태 세명대학교 미디어콘텐츠창작학과 교수는 "AI 데이터 학습과 관련한 법률이나 판례가 충분히 축적되지 않은 상황"이라고 설명했다
다만 정부는 일률적인 요율을 정하기는 어렵다는 입장이다. 주무 부처인 문화체육관광부는 "권리자 단체가 우선 요율안을 마련해야 한다"며 "창작자 단체를 중심으로 대가 산정 논의가 진행 중인 것으로 안다"고 했다. 이어 "정부가 지원하거나 조율할 부분이 있다면 역할을 검토하겠다" 고 덧붙였다.

©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



