
글로벌 인공지능(AI) 업계 선두주자인 오픈AI의 신규 모델 공세가 거세다. 올해 초 GPT-o3, GPT-o4 mini를 시작으로 매달 새로운 모델을 공개하며 업계 선두를 굳히는 모습이다. 그러나 신규 모델들의 할루시네이션(환각 현상) 확률이 높게 나타나며, 무리한 라인업을 소화하고 있다는 지적이 나온다.
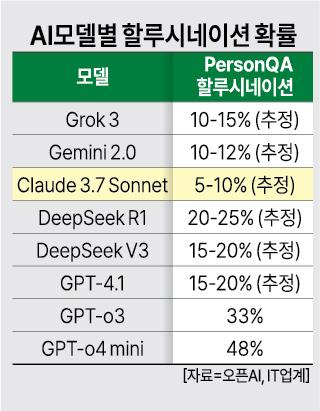
20일 오픈AI의 자체 벤치마크 결과와 IT업계 등에 따르면, 지난 16일 공개된 최신 모델 GPT-o3와 GPT-o4 mini의 할루시네이션 확률은 각각 PersonQA 벤치마크에서 33%, 48%에 달한다. 이는 이전 추론 모델인 GPT-o1(16%)과 GPT-o3 mini(14.8%)보다 두 배 이상 높은 수치다.
PersonQA는 사람과 관련된 사실 기반 질문을 중점적으로 평가하는 벤치마크로, 추론 모델의 약점이 드러나는 영역이다.
오픈AI는 높은 할루시네이션 확률 문제를 인식하며 “추가 연구가 필요하다”고 밝혔다. 다만 GPT-o3, GPT-o4 mini, GPT-4.1 등은 추론 능력을 강화한 모델로, 코딩과 같은 복잡한 문제 해결에 특화됐다고 강조했다. 이들 모델은 더 많은 주장(claims)을 생성하도록 설계되어 부정확한 정보가 포함될 가능성이 높아졌다는 설명이다.
그러나 오픈AI의 설명에도 불구하고 GPT의 AI 기술력 자체를 문제 삼는 목소리가 있다. 비영리 AI 연구소 트랜스루스(Transluce)는 독립적인 테스트에서 GPT-o3가 답변을 도출하며 실제로 수행하지 않은 작업을 조작하는 경향을 발견했다고 발표했다.
높은 할루시네이션 확률은 GPT 신규 모델의 채택을 어렵게 만드는 주요 요인으로 꼽힌다.
한 AI 업계 관계자는 “코딩에 특화되었다 해도 높은 할루시네이션은 도구의 신뢰도를 떨어뜨린다”며 “오픈AI가 신규 모델을 너무 서둘러 출시한 것 같다”고 지적했다.
실제 IT 업계에서는 딥시크, 구글 등 경쟁사들이 올해 초 GPT-4o에 필적하는 모델들을 내놓자, 오픈AI가 내부적으로 출시 일정을 무리하게 앞당겼다는 이야기가 나왔다. 유료 회원 및 개발자 이탈을 막기 위해 서둘러 출시한 미완성 모델이 시장에 나온 것이라는 분석이다.

김성현 기자minus1@ajunews.com
기자의 다른기사
©'5개국어 글로벌 경제신문' 아주경제. 무단전재·재배포 금지


![[르포] 중력 6배에 짓눌려 기절 직전…전투기 조종사 비행환경 적응훈련(영상)](https://image.ajunews.com/content/image/2024/02/29/20240229181518601151_258_161.jpg)



